How to create a chatbot with unlimited memory using OpenAI and Pinecone
In this article, we will explore how to create a chatbot with unlimited memory capabilities using OpenAI and Pinecone.

Creating a chatbot with unlimited memory capabilities can be challenging, especially when it comes to handling large amounts of data. However, with recent advancements in artificial intelligence and natural language processing, it is now possible to create such a chatbot.
In the rest of this article, we will explore how to create a chatbot with unlimited memory capabilities using OpenAI and Pinecone. We will start by discussing the basic concepts of chatbots, natural language processing, and artificial intelligence. Then, we will introduce Pinecone and how it can be used to store and search for data vectors efficiently. Finally, we will walk you through the process of building a chatbot using OpenAI's GPT-3 language model and integrating it with Pinecone. By the end of this article, you will have a good understanding of how to create a chatbot with unlimited memory using OpenAI and Pinecone.
I. Creating a store for episodic and declarative memory and performing semantic search:

1. Mirage Microservices Architecture:
The Mirage microservices architecture is a system of microservices designed for robotics and artificial general intelligence. One of its core components is a vector database that can store and perform semantic searches on data. This architecture is highly scalable, and its components can be run on any platform, making it ideal for building complex systems that require a large amount of data processing.
2. Introduction to Pinecone:
Pinecone is a cloud-based vector database that is designed to handle large amounts of data and perform semantic searches on that data. Pinecone is highly scalable, and it is designed to be easy to use. Pinecone is an excellent database to use for creating chatbots with unlimited memory.
3. The Raven Project:
The Raven project is an open-source project focused on reducing suffering and poverty through the use of natural language processing and artificial intelligence. The Raven project focuses on artificial cognition and data storage using episodic and declarative memory in a vector database. The project aims to create chatbots that can remember and understand conversations over long periods and use this knowledge to provide better responses to users.
4. Using OpenAI Embeddings for Faster Queries and Better Storage Capacity:
OpenAI has created pre-trained language models that can be used to generate high-quality embeddings for natural language processing tasks. These embeddings can be used to perform semantic searches on data and can be used to index large amounts of data for efficient retrieval. The Ada O2 embeddings, which have 1536 output dimensions, are particularly useful for creating chatbots with unlimited memory.
5. Steps for Creating a Chatbot with Unlimited Memory:
To create a chatbot with unlimited memory using OpenAI and Pinecone, follow these steps:

1. Use OpenAI text and Ada O2 embeddings to create a semantic search index for each message:
import openaiimport pinecone# Initialize OpenAI API keyopenai.api_key = "YOUR_API_KEY"# Initialize Pinecone API keypinecone.init(api_key="YOUR_API_KEY", environment="production")# Define the index for the chatbotINDEX_NAME = "chatbot_index"
# Create a Pinecone indexpinecone.create_index(index_name=INDEX_NAME, dimension=1536)# Get messages from a data sourcemessages = ["Hello, how are you?", "What's the weather like today?", "What time is it?", "What is your name?", "How old are you?", "What is your favorite color?"]# Index each message with its corresponding OpenAI embeddingfor message in messages:embedding = openai.Embedding.create(data=[message], model="ada.002")pinecone.index(index_name=INDEX_NAME, data=embedding.vector, ids=[message])
2. Store all messages in the Pinecone index for efficient retrieval:
# Store messages in Pinecone indexfor message in messages:embedding = openai.Embedding.create(data=[message], model="ada.002")pinecone.index(index_name=INDEX_NAME, data=embedding.vector, ids=[message])
3. Use the Pinecone index to perform a semantic search on incoming messages:
# Use Pinecone index to perform semantic searchdef chatbot_response(user_message):embedding = openai.Embedding.create(data=[user_message], model="ada.002")result = pinecone.query(index_name=INDEX_NAME, query_embedding=embedding.vector, top_k=1)return result.ids[0]
By following these steps, you can create a chatbot with unlimited memory using OpenAI and Pinecone. The chatbot will be able to remember and understand conversations over long periods, providing better responses to users.
II. Simplifying code for chat function and retrieving info from Pinecone:
1. Process of iterative development and the need to refactor previous work:
Iterative development is a crucial process in software development that involves refining and improving previous work. This process is essential for creating high-quality code and ensuring that the end product meets the desired specifications. In the case of chatbots, iterative development is especially important as it allows developers to continually improve the bot's ability to respond to user input and generate relevant output.
2. Simplifying a 172-line code script for a chat function and using Davinci03:

To simplify the chat function and retrieve information from Pinecone, we can start by refactoring the previous code. Refactoring involves changing the code's structure without altering its functionality, making it easier to understand and maintain. In this case, we can reduce the 172-line code script to a shorter and simpler version that is easier to read and understand.
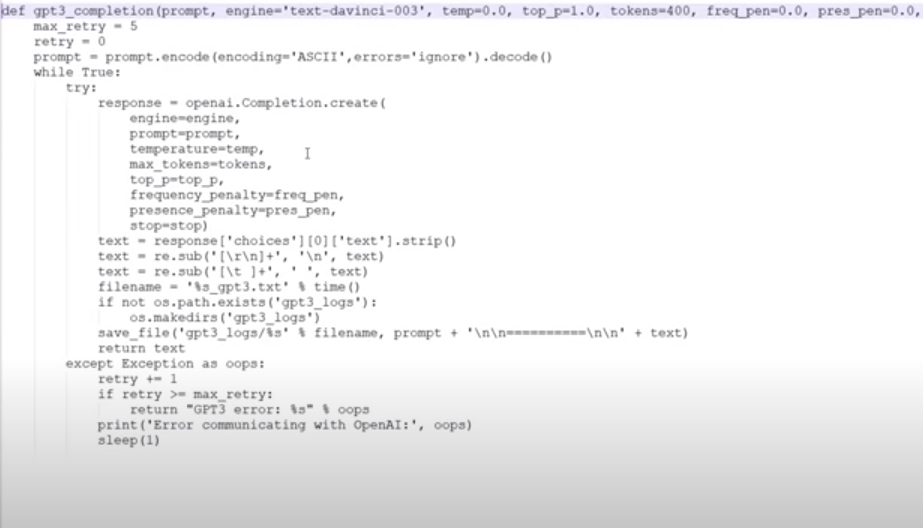
For the chat function, we can use the latest fine-tuned model from OpenAI, Davinci03, with a temperature of zero for deterministic output. This model has unlimited memory and can generate highly relevant responses to user input. By using this model, we can simplify the code and improve the bot's ability to respond to user input.
3. Explanation of the goals of retrieving information from Pinecone:
Retrieving information from Pinecone can help us achieve our goals of reducing suffering, increasing prosperity, and increasing understanding. Pinecone is a cloud-native vector database that can index and search messages with high accuracy and speed. By using Pinecone, we can quickly retrieve information from past conversations and use it to generate more relevant responses to user input.
4. Steps for using Pinecone to index and search for messages, including converting Unix Epoch time stamps to readable formats:
To use Pinecone to index and search for messages, we first need to convert Unix Epoch time stamps to readable formats. This can be done using the following code snippet:
import datetimetimestamp = 1649332800dt_object = datetime.datetime.fromtimestamp(timestamp)print("Readable Date: ", dt_object)
Once the time stamps are converted to readable formats, we can index and search for messages using Pinecone. We can use the following code snippet to index messages:
import pineconepinecone.init(api_key="<YOUR_API_KEY>")pinecone_index = pinecone.Index(index_name="<YOUR_INDEX_NAME>")message
III. Fetching and retrieving messages and metadata in conversational AI:

1. How to query for the top most similar messages and retrieve a list of matches without values:
Fetching and retrieving messages and metadata in conversational AI requires careful consideration of the structure and content of the data. One common approach is to query for the top most similar messages and retrieve a list of matches without values. This allows for the efficient retrieval of relevant memories, which can then be used to generate a response.
2. Discussion of the process of generating responses in conversational AI:
The process of generating responses in conversational AI involves several steps, including fetching memories and using them to generate a response. To fetch a string using an ID and metadata, one can simply include the ID and any relevant metadata in the query. This will return results with a list of dictionaries containing metadata such as the message and timestamp.
3. How to fetch a string using an ID and metadata:
The process of generating responses in conversational AI involves several steps, including fetching memories and using them to generate a response. To fetch a string using an ID and metadata, one can simply include the ID and any relevant metadata in the query. This will return results with a list of dictionaries containing metadata such as the message and timestamp.
4. Including metadata in the query to return results with a list of dictionaries:
Here is an example code snippet demonstrating how to retrieve messages and metadata using Pinecone:
pythonCopy codeimport pinecone# Define Pinecone indexpinecone.init(api_key="your_api_key")index_name = "chatbot_memories"index = pinecone.Index(index_name)# Query for the top 10 most similar messagesquery = "hello"results = index.query(queries=[query], top_k=10)# Retrieve messages and metadata for each resultfor result in results:memory_id = result.idmetadata = result.metadatamessage = index.fetch(ids=[memory_id])[0].dataprint("Memory ID:", memory_id)print("Metadata:", metadata)print("Message:", message)
In this example, we first initialize our Pinecone index and define the name of our index. We then query for the top 10 most similar messages to our query, "hello". For each result, we retrieve the memory ID, metadata, and message using the fetch method. Finally, we print the memory ID, metadata, and message for each result.
IV. Simplify search and retrieval of relevant conversations with Pinecone instant search:

Pinecone offers an instant search feature that simplifies the search and retrieval of relevant conversations. The feature is designed to work with IDs, which are unique identifiers for each conversation. Here are the steps to simplify the search and retrieval of relevant conversations with Pinecone instant search:
Saving metadata separately as a JSON file with a unique ID as the file name and excluding the vector to reduce the burden
It is important to separate metadata, such as message content and timestamp, from the vector to reduce the size of the data being indexed. This can be done by saving the metadata as a JSON file with a unique ID as the file name. Here's an example:
{"message": "Hello, how can I assist you?","timestamp": "2022-04-27 14:30:00"}
1. how the Pinecone instant search only requires IDs and returns a list of dictionaries:
Pinecone instant search only requires IDs to search for relevant conversations. When a search is performed, Pinecone returns a list of dictionaries with matches, which includes the unique IDs and the distances between the query and the matching vectors. To recompose the conversation, a load conversation function is needed to retrieve the metadata associated with each unique ID. Here's an example:
def load_conversation(id):with open(f"{id}.json", "r") as f:conversation = json.load(f)return conversation
2. how to generate a response vectorized with a unique ID and metadata payload, save it as a JSON file in a Nexus folder, and print the output:
To generate a response vectorized with a unique ID and metadata payload, the message content can be passed through the OpenAI API to generate a response. The response can then be vectorized with the unique ID and metadata payload, and saved as a Json file in a Nexus folder. Here's an example:
response = openai_api.generate_response(message)response_vector = pinecone_index.create_vector(response, id=id, metadata=metadata)pinecone_index.upsert(response_vector)with open(f"nexus/{id}.json", "w") as f:json.dump(response_vector, f)print(response)
With these steps, it is possible to simplify the search and retrieval of relevant conversations with Pinecone instant search, while also saving on computational resources by separating metadata from the vector.
V. Raven, a prototype AGI chatbot:
Raven is a prototype AGI chatbot that utilizes Pinecone's infinite memory capabilities and efficient message retrieval to create an AI-powered conversational agent with unlimited memory. The goal of Raven is to demonstrate the power of combining OpenAI's language generation models with Pinecone's vector search capabilities to create a chatbot that can learn and adapt to conversations over time.
One of the key features of Raven is its ability to retrieve messages from Pinecone's index, allowing it to remember and reference past conversations with users. This means that Raven can offer personalized responses to users based on their previous interactions, providing a more human-like conversation experience.
1. Raven's potential applications in reducing poverty and suffering metadata payload:
Raven has the potential to be used in a variety of applications to reduce poverty and suffering, such as providing mental health support, assisting with education, and facilitating access to resources for underserved communities. With its ability to learn and adapt over time, Raven could become a valuable tool for improving the lives of people around the world.
The code snippet below shows how Raven can retrieve messages from Pinecone's index:
import pineconedef search_messages(query):index_name = "messages"results = pinecone.index_query(index_name, query)return results["hits"]def load_conversation(conversation_id):messages = []metadata = {}for message_id in conversation_id:message, metadata = fetch_message(message_id)messages.append(message)return messages, metadatadef fetch_message(message_id):index_name = "messages"result = pinecone.index_get(index_name, message_id)message = result.datametadata = result.metadatareturn message, metadata
In the code snippet above, the search_messages() function queries Pinecone's index for the top most similar messages and retrieves a list of matches without values. The load_conversation() function fetches memories and uses them to generate a response. The fetch_message() function fetches a string using an ID and metadata.
Raven also utilizes Pinecone's instant search feature, which only requires IDs and returns a list of dictionaries with matches. To recompose the conversation, a load_conversation() function is needed. The code snippet below shows how Raven generates a response vectorized with a unique ID and metadata payload, saves it as a JSON file in a Nexus folder, and prints the output:
import jsonimport pineconedef generate_response(query):index_name = "conversations"result = pinecone.index_query(index_name, query, top_k=1)conversation_id = result["hits"][0]["id"]messages, metadata = load_conversation(conversation_id)# code to generate response based on messagesresponse = {"id": conversation_id, "metadata": metadata, "response": "Hello!"}with open(f"nexus/{conversation_id}.json", "w") as f:json.dump(response, f)return responseresponse = generate_response("Hello")print(response)
In the code snippet above, the generate_response() function queries Pinecone's index for the top K most similar conversations and retrieves the conversation ID. The function then loads the conversation using the load_conversation() function and generates a response based on the conversation history. The response is then saved as a JSON file in a Nexus folder with the conversation ID as the filename. Finally, the response is printed to the console.
Conclusion:
In conclusion, building a chatbot with unlimited memory using OpenAI and Pinecone is a powerful application of AI technology, like what is offered by Hybrowlabs Development Services. The ability to retrieve information from past conversations allows chatbots to offer personalized responses that feel more human-like and reduce the burden on human customer service representatives. With Pinecone's fast and efficient search capabilities, it is an excellent tool for creating chatbots with infinite memory. The use of Raven, a prototype AGI chatbot, exemplifies the potential of this technology in reducing poverty and suffering.
FAQ
1. What is Pinecone, and how does it work in creating a chatbot with unlimited memory?
Pinecone is a vector database that allows for fast and efficient search of large data sets. By storing message vectors and metadata separately, chatbots can use Pinecone to search for and retrieve relevant information from past conversations.
2. How can OpenAI's language models be fine-tuned for chatbot applications?
OpenAI's language models can be fine-tuned for chatbot applications by training them on specific data sets and adjusting parameters such as temperature to control the level of randomness in their responses.
3. What is Raven, and how does it use Pinecone and OpenAI to create an AGI chatbot?
Raven is a prototype AGI chatbot that uses Pinecone's infinite memory capabilities and OpenAI's language models to offer personalized responses based on past conversations. It uses a combination of neural networks and decision-making algorithms to generate responses that feel more human-like.
4. What are the potential benefits of building chatbots with infinite memory capabilities?
Chatbots with infinite memory capabilities can reduce the burden on human customer service representatives, offer personalized responses based on past conversations, and improve the overall customer experience.
5. What are some potential ethical concerns with using AGI chatbots?
Some potential ethical concerns with using AGI chatbots include privacy concerns, the risk of AI bias, and the potential loss of jobs for human customer service representatives. It's important to ensure that chatbots are developed and used in an ethical and responsible manner.
No comments yet. Login to start a new discussion Start a new discussion